December 2022
Common Content Package Available on npm
Package @sap/cds-common-content is now available on npm. It provides prebuilt data for the common entities Countries, Currencies, and Languages.
Add it like so:
npm add @sap/cds-common-content --saveAdd this to your cds files:
using from '@sap/cds-common-content';Learn more about types and aspects from @sap/cds/commonLearn more about integrating reuse packages
Open Source GraphQL Adapter
We have released our first module @cap-js/graphql to public GitHub. It's the successor of @sap/cds-graphql. Use this from now on instead.
Also note the new plugin mechanism. It requires the middlewares feature and, by default, mounts the protocol adapter behind the authentication middleware.
{
"cds": {
"requires": {
"middlewares": true
},
"protocols": {
"graphql": { "path": "/graphql", "impl": "@cap-js/graphql" }
}
}
}Learn more about the new GraphQL Adapter at our public repository.
Multitenant CAP Sample Application
Based on a recent partner collaboration we are pleased to feature another comprehensive CAP sample application. Besides demonstrating various Multitenancy aspects, the solution touches on a lot of other essential topics like SAP BTP Automation, User-Management, or a push-based API Integration. Even a lot of Day-2 Operations are covered in the so-called Expert Scope. Start by reading the recently published blog post series and deep dive into the related SAP-samples GitHub repository to learn more.
Blog SeriesSample Application incl. documentation
New Performance Modeling Guide
The new Performance Modeling guide is the start of a series of performance-related documents. We'll promote additions to this series in our release notes.
Read the new Performance Modeling guide.
Initial Data for Extensions
Besides local test data, extensions can now contain initial data as CSV files.
Learn more about initial data in Extensions.
Migration Helper for MTX beta
In order to migrate your application from using @sap/mtx to @sap/mtxs, you can now run a script to convert the subscription metadata and the extensions to the persistence used by @sap/cds-mtxs.
Learn more about the script in the Migration Guide.
Automatic Schema Migration for SQLite beta
WARNING
This is a beta feature. Its configuration and how it works may change in future releases.
Compatible model changes can now be deployed by evolving the database schema instead of applying DROP/CREATE. Switch on automatic schema evolution in the database configuration:
"db": {
"kind": "sqlite",
"schema_evolution": "auto"
}CDS Language & Compiler
OData Annotation @Validation.AllowedValues for all enums
The values of an enum type are now always rendered in the generated EDMX as @Validation.AllowedValues, irrespective of @assert.range.
Node.js
Important Changes ❗️
- Errors thrown by the Database Service do not have a status code anymore. Eventually, they end up in an internal server error (status code 500). Previously, the runtime differentiated between actual SQL errors and input validation. As the origin of the query is unknown to the Database Service, it must not always be treated as user input.
- Data provided for associations (except primary keys in managed associations) within a deep insert/update is from now on ignored by the Database Service. Previously, it was erroneously rejected as a Bad Request assuming that it always serves an HTTP endpoint.
UPSERT
Flat UPSERT queries are now supported. It updates existing data or inserts new data if not yet existing and is primarily intended for efficient data replication scenarios. It eventually unfolds to an UPSERT SQL statement on SAP HANA and to an INSERT ON CONFLICT SQL statement on SQLite.
UPSERT is only available for database services. It can be used in custom handlers but the generic handlers of the runtime do not make use of it.
You can use it like:
UPSERT.into('db.Books')
.entries({ ID: 4711, title: 'Wuthering Heights', stock: 100 })CSRF Token Handling for Remote Services
The automatic fetch of CSRF tokens of consumed services is now controllable for each service individually.
"cds": {
"requires": {
"API_BUSINESS_PARTNER": {
"kind": "odata-v2",
"model": "srv/external/API_BUSINESS_PARTNER",
"csrf": true
}
}
}WARNING
The global configuration cds.features.fetch_csrf is deprecated and will be removed in the next major version 7.
Learn more about Consuming Remote Services in general.
Java
Deep Update / Upsert with nested Deltas
CAP Java now supports delta lists with related entities in deep updates and upserts, which allow a more efficient execution.
OData: Update Related Entities using Delta Payload
So far OData PATCH requests that update related entities (deep updates) have to provide data for related entities using a full set payload. Related entities that are not in the update data are deleted.
As an alternative it is possible now to specify the related entities as nested delta payload. In this case, only the entities contained in the delta payload are processed. Related entities that are not in the delta remain untouched.
{
"ID": "o1",
"Items@delta": [
{
"ID": "oi1",
"amount": 101
},
{
"@id": "OrderItems(oi2)",
"@removed": { "reason": "deleted" }
}
]
}The example update payload for Order(o1) contains a nested delta payload for the associated order items. Upon executing the PATCH request, order item oi1 is upserted (inserted or updated as needed), and item oi2 is deleted. All other items of Order(o1) remain untouched.
Using Deltas in CDS QL
When executing deep update or deep upsert statements, associated entities can now also be represented as a delta.
To use the delta representation, create a CdsList that is marked as delta and explicitly mark entities to be deleted via the CdsData:forRemoval method.
OrderItems item1 = OrderItems.create("oi1");
item1.setAmount(101);
OrderItems item2 = OrderItems.create("oi2");
Orders order = Orders.create("o1");
order.setItems(delta(item1, item2.forRemoval()));
Update.entity(ORDERS).data(order);This update data for Order(o1) contains a nested delta list (CdsList marked as delta) for Items. The delta contains data for item oi1 and item oi2 is marked for removal. During execution item oi1 is upserted and item oi2 is deleted, all other items of Order(o1) remain untouched.
Optimized OData V4 Adapter
Creating a JSON-response on basis of the OData query's result is a pretty CPU-intensive task in the OData protocol adapters. The previous implementation of the V4 adapter is based on Apache Olingo APIs that require the full query result set to be transferred into an intermediate data representation before it is serialized to the servlet stream in JSON format.
With this version, an optimized implementation of OData V4 serializer is introduced which directly writes the result data to the response stream. This significantly reduces memory and CPU consumption helping to scale the number of requests to a higher degree. To cope with errors during streaming, it makes use of OData in-stream error handling.
The measurements of basic OData requests in SFlight application has been redone with the current version (optimized OData serializer mode activated):
| OData Request1 | CAP Java 1.26.0 | CAP Java 1.29.0 | CAP Java 1.30.0 |
|---|---|---|---|
GET /Travel?$top=1000 | 100% | 31% | 13% |
GET /Travel?$expand=to_Agency | 100% | 39% | 16% |
GET /Travel?$expand=to_Booking($expand=to_Carrier) | 100% | 21% | 11% |
GET /Travel?$search=Japan | 100% | 46% | 29% |
GET /Travel(TravelUUID=<uuid>,IsActive=true) | 100% | 130% | 50% |
1 No authorization and in-memory DB H2
The optimized serializer is optional and can be switched on with cds.odatav4.serializer.enabled: true. If enabled, only OData requests with system option $apply still make use of the classic serializer.
Exception Handler for Messaging
To ensure successful delivery of messages, some messaging brokers such as Event Mesh and Message Queuing rely on the acknowledgement of sent messages. These brokers redeliver messages that are not acknowledged by the receiver. By default, CAP acknowledges messages only if they have been successfully handled by the application. Hence, repeatedly failing messages are redelivered again and again, regardless of the root cause.
To avoid this situation and to introduce an application-specific error handling, you can now register an error handler for messaging services in order to explicitly control message acknowledgement in case an exception has occurred:
@On(service = "messaging")
private void handleError(MessagingErrorEventContext context) {
// access the event context of the raised exception
context.getException().getEventContexts().stream().findFirst().ifPresent(expContext -> {
TopicMessageEventContext messageEventContext = expContext.as(TopicMessageEventContext.class);
String event = messageEventContext.getEvent();
String data = messageEventContext.getData();
// handle the message according to event and data
// ...
});
context.setResult(true); // finally acknowledge the message
}Learn more about Error Handling.
Additional Persistence Services
The CAP Java SDK now automatically configures additional Persistence Services for each non-primary database service binding. This enables simple CQN-based access to an additional tenant-independent HDI container in multitenant applications. Simply bind an additional HDI container to your application and a Persistence Service with the name of the service binding is automatically configured by CAP. Any usage of an additional Persistence Service needs to happen in custom handlers.
Note that all Persistence Service instances reflect on the same CDS model. It is the responsibility of the developer to decide which artifacts are deployed into which database at deploy time and to access these artifacts with the respective Persistence Service at runtime.
You can also now configure additional Persistence Services for non-primary datasources that are explicitly created as beans in Spring Boot. All details about Persistence Services can now be found in the new Java > Persistence Services guide.
Type Propagation
For the functions min, max, count*, tolower, toupper and substring the result type is now determined considering the input type.
Sample entity:
entity Orders {
ID : UUID;
created : Timestamp;
}Query:
Select.from(ORDERS).columns(o -> o.created().max().as("mx"));Returns data with an element mx with Java type java.time.Instant.
Miscellaneous
The expand execution now also optimizes the
to-oneexpands that have nestedto-manyexpands, resulting in less queries against the data store.In CSV initialization mode
always, CAP Java creates now CSV data with UPSERT so that the initialization can be used with a persistent database.Generated accessor and builder interfaces are now annotated with
@Generatedso that they can be identified by static code analysis as such.CAP Java now reduces the size of CDS models. As UI Annotations aren't needed in the backend, it strips the UI annotations from the CDS model and preserves them only in EDMX.
The
DataSourcebeans created by CAP Java based on service bindings are now namedds-<binding>instead of<binding>. Now a Persistence Service bean is auto-configured with name<binding>.The query parameter
sap-languageis based on SAP's proprietary language tags. CAP Java however supports BCP47 language tags only. Thereforesap-languagewas replaced bysap-localewhich is based on BCP47 language tags.
Tools
New CAP Sample Notebook
The Extending SaaS Applications guide is now available as a CAP Notebook.
Add Variables to CAP Notebooks
CAP Notebooks now support variable declarations in a cell which can be used later in shell cells, terminal cells or any magic command. This offers the possibility to declare values once, like host names or ports, and reuse them across the notebook.
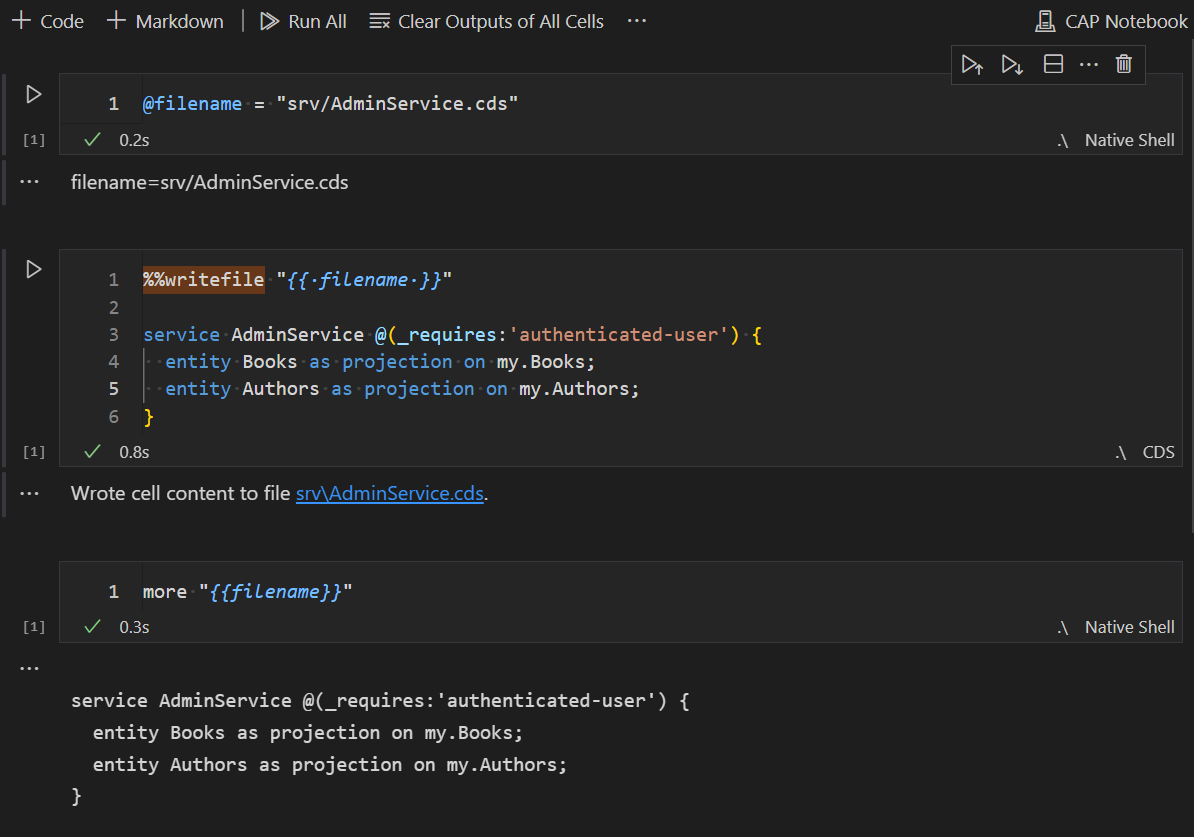
Support for Specific CDS Compiler Versions in VS Code
This release of our VS Code extension introduces a special handling for projects using older (version < 3) compilers. If your workspace contains exclusively projects using CDS compiler version 2 or lower, a specialized CDS language support will be started. This enhancements comes with a change, which doesn't allow mixing CDS compiler versions in one workspace anymore. In such cases, our extension shows a warning message and informs you to separate your projects into workspaces, one workspace for each compiler version.

Improved Migration Table Support in cds build
With this version, only model entities annotated with @cds.persistence.journal are saved as last-dev version in the file system. This ensures that changes are reduced to the minimum.
WARNING
You will observe unexpectedly big diffs after the first execution of cds build.
Multitenancy
Minimum runtime version required
@sap/cds-mtxs version >= 1.4.0 requires at least @sap/cds@6.4.0 or CAP Java 1.30.1.
Enhanced job status response for asynchronous APIs
With the @sap/cds-mtxs library, you can now poll the status of the individual tenants for the asynchronous upgrade call.
Persistence of onboarding metadata
The metadata that is sent to the application by the SAP BTP SaaS Provisioning service with the subscription is now persisted. It can be read using
GET /-/cds/saas-provisioning/tenant/<tenant id>You can omit the tenant id to get the metadata of all tenants.