Getting Started in a Nutshell
Build Your First App with CAP
Jumpstart a Project
After you completed the Initial Setup, you jumpstart a project as follows:
Create a new project using
cds initshcds init bookshopshcds init bookshop --java --java:mvn -DgroupId=com.sap.capireOpen the project in VS Code
shcode bookshopAssumes you activated the
codecommand on macOS as documentedFor Java development in VS Code you need to install extensions.
Run the following command in an Integrated Terminal
shcds watchshcd srv && mvn cds:watchcds watchis waiting for things to come...log[dev] cds w cds serve all --with-mocks --in-memory? live reload enabled for browsers ___________________________ No models found in db/,srv/,app/,schema,services. Waiting for some to arrive...So, let's go on feeding it...
Optionally clone sample from GitHub ...
The sections below describe a hands-on walkthrough, in which you'd create a new project and fill it with content step by step. Alternatively, you can get the final sample content from GitHub as follows:
git clone https://github.com/sap-samples/cloud-cap-samples samples
cd samples
npm installgit clone https://github.com/sap-samples/cloud-cap-samples-java bookshopNote: When comparing the code from the cap/samples on GitHub to the snippets given in the sections below you will recognise additions showcasing enhanced features. So, what you find in there is a superset of what we describe in this getting started guide.
Capture Domain Models
Let's feed our project by adding a simple domain model. Start by creating a file named db/schema.cds and copy the following definitions into it:
using { Currency, managed, sap } from '@sap/cds/common';
namespace sap.capire.bookshop;
entity Books : managed {
key ID : Integer;
title : localized String(111);
descr : localized String(1111);
author : Association to Authors;
genre : Association to Genres;
stock : Integer;
price : Decimal(9,2);
currency : Currency;
}
entity Authors : managed {
key ID : Integer;
name : String(111);
books : Association to many Books on books.author = $self;
}
/** Hierarchically organized Code List for Genres */
entity Genres : sap.common.CodeList {
key ID : Integer;
parent : Association to Genres;
children : Composition of many Genres on children.parent = $self;
}Find this source also in cap/samples for Node.js, and for JavaLearn more about Domain Modeling.Learn more about CDS Modeling Languages.
Deployed to Databases
As soon as you save the schema.cds file, the still running cds watch reacts immediately with new output like this:
[cds] - connect to db > sqlite { database: ':memory:' }
/> successfully deployed to in-memory database.This means that cds watch detected the changes in db/schema.cds and automatically bootstrapped an in-memory SQLite database when restarting the server process.
As soon as you save your CDS file, the still running mvn cds:watch command reacts immediately with a CDS compilation and reload of the CAP Java application. The embedded database of the started application will reflect the schema defined in your CDS file.
Compiling Models
We can optionally test-compile models individually to check for validity and produce a parsed output in CSN format. For example, run this command in a new terminal:
cds db/schema.cdsThis dumps the compiled CSN model as a plain JavaScript object to stdout.
Add --to <target> (shortcut -2) to produce other outputs, for example:
cds db/schema.cds -2 json
cds db/schema.cds -2 yml
cds db/schema.cds -2 sqlLearn more about the command line interface by executing cds help.
Providing Services
After the recent changes, cds watch also prints this message:
No service definitions found in loaded models.
Waiting for some to arrive...After the recent changes, the running CAP Java application is still not exposing any service endpoints.
So, let's go on feeding it with two service definitions for different use cases:
An AdminService for administrators to maintain Books and Authors.
A CatalogService for end users to browse and order Books under path /browse.
To do so, create the following two files in folder ./srv and fill them with this content:
using { sap.capire.bookshop as my } from '../db/schema';
service AdminService @(requires:'authenticated-user') {
entity Books as projection on my.Books;
entity Authors as projection on my.Authors;
}using { sap.capire.bookshop as my } from '../db/schema';
service CatalogService @(path:'/browse') {
@readonly entity Books as select from my.Books {*,
author.name as author
} excluding { createdBy, modifiedBy };
@requires: 'authenticated-user'
action submitOrder (book: Books:ID, quantity: Integer);
}Find this source also on GitHub for Node.js, and for Java
Learn more about Defining Services.
Served via OData
This time cds watch reacted with additional output like this:
[cds] - serving AdminService { at: '/odata/v4/admin' }
[cds] - serving CatalogService { at: '/browse' }
[cds] - server listening on { url: 'http://localhost:4004' }As you can see, the two service definitions have been compiled and generic service providers have been constructed to serve requests on the listed endpoints /odata/v4/admin and /browse.
In case the CDS service definitions were compiled correctly the Spring Boot runtime is reloaded automatically and should output a log line like this:
c.s.c.services.impl.ServiceCatalogImpl : Registered service AdminService
c.s.c.services.impl.ServiceCatalogImpl : Registered service CatalogServiceAs you can see in the log output, the two service definitions have been compiled and generic service providers have been constructed to serve requests on the listed endpoints /odata/v4/AdminService and /odata/v4/browse.
Add the dependency to spring-boot-security-starter
Both services defined above contain security annotations that restrict access to certain endpoints. Please add the dependency to spring-boot-security-starter to the srv/pom.xml in order to activate mock user and authentication support:
mvn com.sap.cds:cds-maven-plugin:add -Dfeature=SECURITYTIP
CAP-based services are full-fledged OData services out of the box. Without adding any provider implementation code, they translate OData request into corresponding database requests, and return the results as OData responses.
Learn more about Generic Providers.
Generating APIs
We can optionally also compile service definitions explicitly, for example to OData EDMX metadata documents:
cds srv/cat-service.cds -2 edmxEssentially, using a CLI, this invokes what happened automatically behind the scenes in the previous steps. While we don't really need such explicit compile steps, you can do this to test correctness on the model level, for example.
Generic index.html
Open http://localhost:4004 in your browser and see the generic index.html page:

Note: User
aliceis a default user with admin privileges. Use it to access the /admin service. You don't need to enter a password.
Open http://localhost:8080 in your browser and see the generic index.html page:

Note: User
authenticatedis a prepared mock user which will be authenticated by default. Use it to access the /admin service. You don't need to enter a password.
Using Databases
SQLite In-Memory
As previously shown, cds watch automatically bootstraps an SQLite in-process and in-memory database by default — that is, unless told otherwise. While this isn't meant for productive use, it drastically speeds up development turn-around times, essentially by mocking your target database, for example, SAP HANA.
H2 In-Memory
As previously shown, mvn cds:watch automatically bootstraps an H2 in-process and in-memory database by default — that is, unless told otherwise. While this isn't meant for productive use, it drastically speeds up turn-around times in local development and furthermore allows self-contained testing.
Adding Initial Data
Now, let's fill your database with initial data by adding a few plain CSV files under db/data like this:
ID,title,author_ID,stock
201,Wuthering Heights,101,12
207,Jane Eyre,107,11
251,The Raven,150,333
252,Eleonora,150,555
271,Catweazle,170,22ID,name
101,Emily Brontë
107,Charlotte Brontë
150,Edgar Allen Poe
170,Richard Carpentercds add data can help you with the file and record generation
Create empty CSV files with header lines only:
cds add dataCreate CSV files that already include some sample data:
cds add data --records 10Find a full set of .csv files in cap/samples.
After you've added these files, cds watch restarts the server with output, telling us that the files have been detected and their content has been loaded into the database automatically:
[cds] - connect to db { database: ':memory:' }
> filling sap.capire.bookshop.Authors from bookshop/db/data/sap.capire.bookshop-Authors.csv
> filling sap.capire.bookshop.Books from bookshop/db/data/sap.capire.bookshop-Books.csv
> filling sap.capire.bookshop.Books_texts from bookshop/db/data/sap.capire.bookshop-Books_texts.csv
> filling sap.capire.bookshop.Genres from bookshop/db/data/sap.capire.bookshop-Genres.csv
> filling sap.common.Currencies from common/data/sap.common-Currencies.csv
> filling sap.common.Currencies_texts from common/data/sap.common-Currencies_texts.csv
/> successfully deployed to in-memory database.Note: This is the output when you're using the samples. It's less if you've followed the manual steps here.
After you've added these files, mvn cds:watch restarts the server with output, telling us that the files have been detected and their content has been loaded into the database automatically:
c.s.c.s.impl.persistence.CsvDataLoader : Filling sap.capire.bookshop.Books from db/data/sap.capire.bookshop-Authors.csv
c.s.c.s.impl.persistence.CsvDataLoader : Filling sap.capire.bookshop.Books from db/data/sap.capire.bookshop-Books.csvLearn more about Using Databases.
Querying via OData
Now that we have a connected, fully capable SQL database, filled with some initial data, we can send complex OData queries, served by the built-in generic providers:
- …/Books?$select=ID,title
- …/Authors?$search=Bro
- …/Authors?$expand=books($select=ID,title)
- …/Books?$select=ID,title
- …/Authors?$search=Bro
- …/Authors?$expand=books($select=ID,title)
Note: Use alice as user to query the
adminservice. You don't need to enter a password.
Note: Use authenticated to query the
adminservice. You don't need to enter a password.
Learn more about Generic Providers.Learn more about OData's Query Options.
Persistent Databases
Instead of in-memory databases we can also use persistent ones. For example, still with SQLite, add the following configuration:
{
"cds": {
"requires": {
"db": {
"kind": "sqlite",
"credentials": { "url": "db.sqlite" }
}
}
}
}Then deploy:
cds deployThe difference from the automatically provided in-memory database is that we now get a persistent database stored in the local file ./db.sqlite. This is also recorded in the package.json.
To see what that did, use the sqlite3 CLI with the newly created database.
sqlite3 db.sqlite .dump
sqlite3 db.sqlite .tablesLearn how to install SQLite on Windows.
You could also deploy to a provisioned SAP HANA database using this variant.
cds deploy --to hanaLearn more about deploying to SAP HANA.
Serving UIs
You can consume the provided services, for example, from UI frontends, using standard AJAX requests. Simply add an index.html file into the app/ folder, to replace the generic index page.
SAP Fiori UIs
CAP provides out-of-the-box support for SAP Fiori UIs, for example, with respect to SAP Fiori annotations and advanced features such as search, value helps and SAP Fiori Draft.
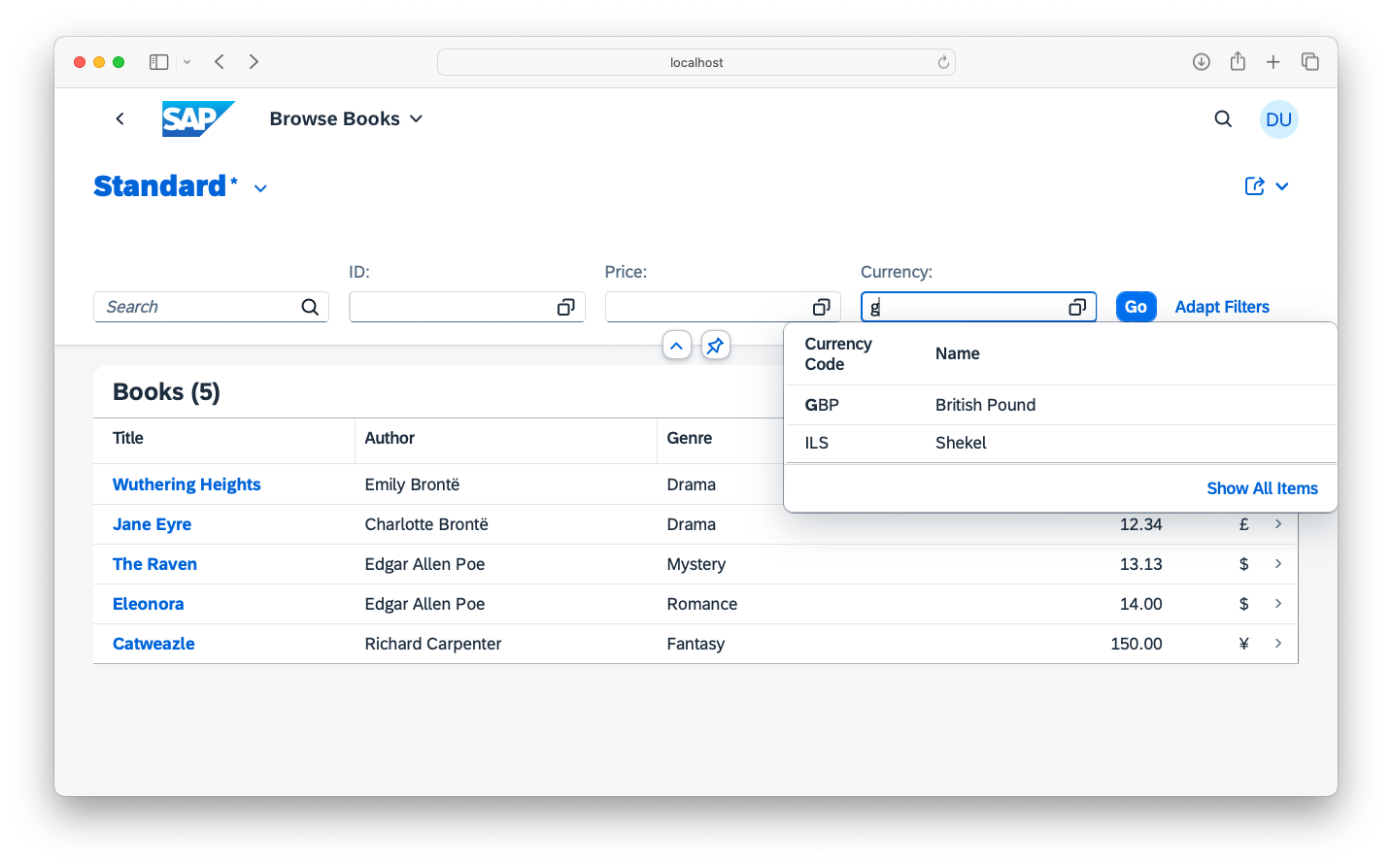
Learn more about Serving Fiori UIs.
Vue.js UIs
Besides Fiori UIs, CAP services can be consumed from any UI frontends using standard AJAX requests. For example, you can find a simple Vue.js app in cap/samples, which demonstrates browsing and ordering books using OData requests to the CatalogService API we defined above.
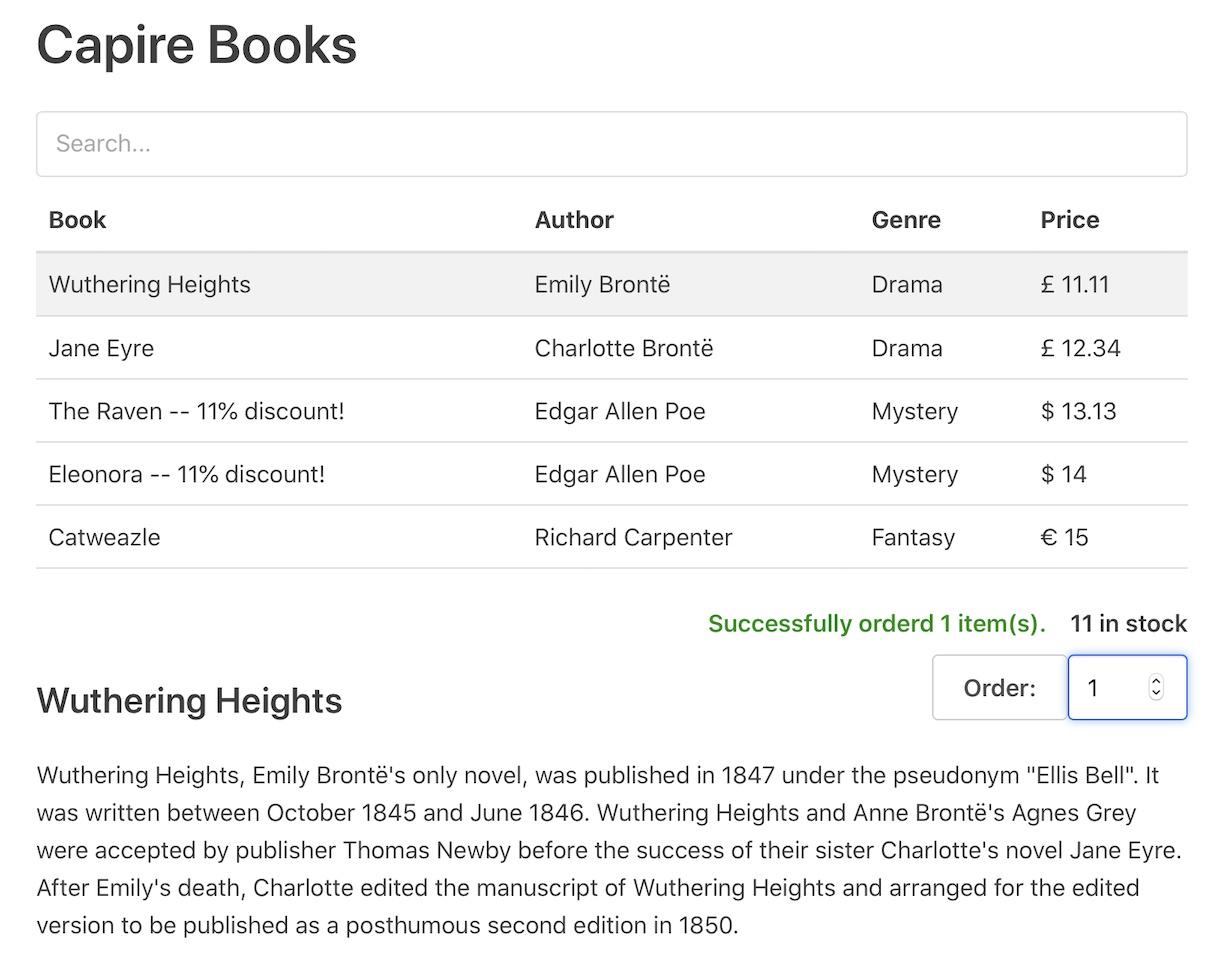
Adding Custom Logic
While the generic providers serve most CRUD requests out of the box, you can add custom code to deal with the specific domain logic of your application.
Service Implementations
In Node.js, the easiest way to provide implementations for services is through equally named .js files placed next to a service definition's .cds file:
bookshop/
├─ srv/
│ ├─ ...
│ ├─ cat-service.cds
│ └─ cat-service.js
└─ ...See these files also in cap/samples/bookshop/srv folder.Learn more about providing service implementations in Node.js.Learn also how to do that in Java using Event Handler Classes.
You can have this .js file created automatically with cds add handler.
In CAP Java, you can add custom handlers for your service as so called EventHandlers. As CAP Java integrates with Spring Boot, you need to provide your custom code in classes, annotated with @Component, for example. Use your favorite Java IDE to add a class like the following to the srv/src/main/java/ folder of your application.
@Component
@ServiceName(CatalogService_.CDS_NAME)
public class CatalogServiceHandler implements EventHandler {
// your custom code will go here
}TIP
Place the code in your package of choice and use your IDE to generate the needed import statements.
Adding Event Handlers
Service implementations essentially consist of one or more event handlers.
Copy this into srv/cat-service.js to add custom event handlers:
const cds = require('@sap/cds')
class CatalogService extends cds.ApplicationService { init() {
const { Books } = cds.entities('CatalogService')
// Register your event handlers in here, for example:
this.after ('each', Books, book => {
if (book.stock > 111) {
book.title += ` -- 11% discount!`
}
})
return super.init()
}}
module.exports = CatalogServiceLearn more about adding event handlers using <srv>.on/before/after.
Now that you have created the classes for your custom handlers it's time to add the actual logic. You can achieve this by adding methods annotated with CAP's @Before, @On, or @After to your new class. The annotation takes two arguments: the event that shall be handled and the entity name for which the event is handled.
@After(event = CqnService.EVENT_READ, entity = Books_.CDS_NAME)
public void addDiscountIfApplicable(List<Books> books) {
for (Books book : books) {
if (book.getStock() != null && book.getStock() > 111) {
book.setTitle(book.getTitle() + " -- 11% discount!");
}
}
}Code including imports
package com.sap.capire.bookshop.handlers;
import java.util.List;
import org.springframework.stereotype.Component;
import com.sap.cds.services.cds.CqnService;
import com.sap.cds.services.handler.EventHandler;
import com.sap.cds.services.handler.annotations.After;
import com.sap.cds.services.handler.annotations.ServiceName;
import cds.gen.catalogservice.Books;
import cds.gen.catalogservice.Books_;
import cds.gen.catalogservice.CatalogService_;
@Component
@ServiceName(CatalogService_.CDS_NAME)
public class CatalogServiceHandler implements EventHandler {
@After(event = CqnService.EVENT_READ, entity = Books_.CDS_NAME)
public void addDiscountIfApplicable(List<Books> books) {
for (Books book : books) {
if (book.getStock() != null && book.getStock() > 111) {
book.setTitle(book.getTitle() + " -- 11% discount!");
}
}
}
}Learn more about event handlers in the CAP Java documentation.
Consuming Other Services
Quite frequently, event handler implementations consume other services, sending requests and queries, as in the completed example below.
const cds = require('@sap/cds')
class CatalogService extends cds.ApplicationService { async init() {
const db = await cds.connect.to('db') // connect to database service
const { Books } = db.entities // get reflected definitions
// Reduce stock of ordered books if available stock suffices
this.on ('submitOrder', async req => {
const {book,quantity} = req.data
const n = await UPDATE (Books, book)
.with ({ stock: {'-=': quantity }})
.where ({ stock: {'>=': quantity }})
n > 0 || req.error (409,`${quantity} exceeds stock for book #${book}`)
})
// Add some discount for overstocked books
this.after ('each','Books', book => {
if (book.stock > 111) book.title += ` -- 11% discount!`
})
return super.init()
}}
module.exports = CatalogService@Component
@ServiceName(CatalogService_.CDS_NAME)
public class SubmitOrderHandler implements EventHandler {
private final PersistenceService persistenceService;
public SubmitOrderHandler(PersistenceService persistenceService) {
this.persistenceService = persistenceService;
}
@On
public void onSubmitOrder(SubmitOrderContext context) {
Select<Books_> byId = Select.from(cds.gen.catalogservice.Books_.class).byId(context.getBook());
Books book = persistenceService.run(byId).single().as(Books.class);
if (context.getQuantity() > book.getStock())
throw new IllegalArgumentException(context.getQuantity() + " exceeds stock for book #" + book.getTitle());
book.setStock(book.getStock() - context.getQuantity());
persistenceService.run(Update.entity(Books_.CDS_NAME).data(book));
context.setCompleted();
}
}Code including imports
package com.sap.capire.bookshop.handlers;
import org.springframework.stereotype.Component;
import com.sap.cds.ql.Select;
import com.sap.cds.ql.Update;
import com.sap.cds.services.handler.EventHandler;
import com.sap.cds.services.handler.annotations.On;
import com.sap.cds.services.handler.annotations.ServiceName;
import com.sap.cds.services.persistence.PersistenceService;
import cds.gen.catalogservice.Books;
import cds.gen.catalogservice.Books_;
import cds.gen.catalogservice.CatalogService_;
import cds.gen.catalogservice.SubmitOrderContext;
@Component
@ServiceName(CatalogService_.CDS_NAME)
public class SubmitOrderHandler implements EventHandler {
private final PersistenceService persistenceService;
public SubmitOrderHandler(PersistenceService persistenceService) {
this.persistenceService = persistenceService;
}
@On
public void onSubmitOrder(SubmitOrderContext context) {
Select<Books_> byId = Select.from(cds.gen.catalogservice.Books_.class).byId(context.getBook());
Books book = persistenceService.run(byId).single().as(Books.class);
if (context.getQuantity() > book.getStock())
throw new IllegalArgumentException(context.getQuantity() + " exceeds stock for book #" + book.getTitle());
book.setStock(book.getStock() - context.getQuantity());
persistenceService.run(Update.entity(Books_.CDS_NAME).data(book));
context.setCompleted();
}
}Find this source also in cap/samples.Find this source also in cap/samples.Learn more about connecting to services using cds.connect.Learn more about connecting to services using @Autowired, com.sap.cds.ql, etc.Learn more about reading and writing data using cds.ql.Learn more about reading and writing data using cds.ql.Learn more about using reflection APIs using <srv>.entities.Learn more about typed access to data using the CAP Java SDK.
Test this implementation, for example using the Vue.js app, and see how discounts are displayed in some book titles.
Sample HTTP Requests
Test the implementation by submitting orders until you see the error messages. Create a file called test.http and copy the request into it.
### Submit Order
POST http://localhost:4004/browse/submitOrder
Content-Type: application/json
Authorization: Basic alice:
{
"book": 201,
"quantity": 2
}### Submit Order
POST http://localhost:8080/odata/v4/browse/submitOrder
Content-Type: application/json
Authorization: Basic authenticated:
{
"book": 201,
"quantity": 2
}Summary
With this getting started guide we introduced many of the basics of CAP, such as:
Visit the Cookbook for deep dive guides on these topics and more. Also see the reference documentations for CDS, as well as Node.js and Java Service SDKs and runtimes.