
Observability
Presents a set of recommended tools that help to understand the current status of running CAP services.
Logging
When tracking down erroneous behavior, application logs often provide useful hints to reconstruct the executed program flow and isolate functional flaws. In addition, they help operators and supporters to keep an overview about the status of a deployed application. In contrast, messages created using the Messages API in custom handlers are reflected to the business user who has triggered the request.
Logging Façade
Various logging frameworks for Java have evolved and are widely used in Open Source software. Most prominent are logback, log4j, and JDK logging (java.util.logging or briefly jul). These well-established frameworks more or less deal with the same problem domain, that is:
- Logging API for (parameterized) messages with different log levels.
- Hierarchical logger components that can be configured independently.
- Separation of log input (messages, parameters, context) and log output (format, destination).
CAP Java SDK seamlessly integrates with Simple Logging Façade for Java (SLF4J), which provides an abstraction layer for logging APIs. Applications compiled against SLF4J are free to choose a logging framework implementation at deployment time. Most famous libraries have a native integration to SLF4J, but it also can bridge legacy logging API calls:
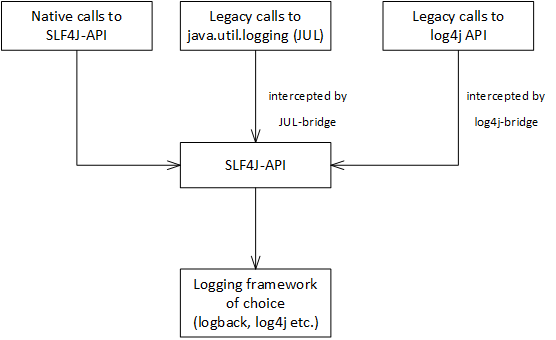
Logger API
The SLF4J API is simple to use. Retrieve a logger object, choose the log method of the corresponding log level and compose a message with optional parameters via the Java API:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
Logger logger = LoggerFactory.getLogger("my.loggers.order.consolidation");
@After(event = CqnService.EVENT_READ)
public void readAuthors(List<Orders> orders) {
orders.forEach(order -> {
logger.debug("Consolidating order {}", order);
consolidate(order);
});
logger.info("Consolidated {} orders", orders.size());
}Some remarks:
- Spring Boot Logging shows how to configure loggers individually to control the emitted log messages.
- The API is robust with regards to the passed parameters, which means no exception is thrown on parameters mismatch or invalid parameters.
Tip
Prefer passing parameters over concatenating the message. logger.info("Consolidating order " + order) creates the message String regardless the configured log level. This can have a negative impact on performance.
Tip
A ServiceException thrown in handler code and indicating a server error (that is, HTTP response code 5xx) is automatically logged as error along with a stacktrace.
Spring Boot Logging
To set up a logging system, a concrete logging framework has to be chosen and, if necessary, corresponding SLF4j adapters. In case your application runs on Spring Boot and you use the Spring starter packages, you most likely don't have to add any explicit dependency, as the bundle spring-boot-starter-logging is part of all Spring Boot starters. It provides logback as default logging framework and in addition adapters for the most common logging frameworks (log4j and jul).
Similarly, no specific log output configuration is required for local development, as per default, log messages are written to the console in human-readable form, which contains timestamp, thread, and logger component information. To customize the log output, for instance to add some application-specific information, you can create corresponding configuration files (such as logback-spring.xml for logback). Add them to the classpath and Spring picks them automatically. Consult the documentation of the dedicated logging framework to learn about the configuration file format.
All logs are written, that have a log level greater or equal to the configured log level of the corresponding logger object. The following log levels are available:
| Level | Use case |
|---|---|
OFF | Turns off the logger |
TRACE | Tracks the application flow only |
DEBUG | Shows diagnostic messages |
INFO | Shows important flows of the application (default level) |
WARN | Indicates potential error scenarios |
ERROR | Shows errors and exceptions |
With Spring Boot, there are different convenient ways to configure log levels in a development scenario, which is explained in the following section.
At Compile Time
The following log levels can be configured:
# Set new default level
logging.level.root: WARN
# Adjust custom logger
logging.level.my.loggers.order.Consolidation: INFO
# Turn off all loggers matching org.springframework.*:
logging.level.org.springframework: OFF
# Turn on debug logging for sql statements and messaging:
logging.level:
com.sap.cds.persistence.sql: DEBUG
com.sap.cds.messaging: DEBUGNote that loggers are organized in packages, for instance org.springframework controls all loggers that match the name pattern org.springframework.*.
At Runtime with Restart
You can overrule the given logging configuration with a corresponding environment variable. For instance, to set loggers in package my.loggers.order to DEBUG level set the following environment variable:
LOGGING_LEVEL_MY_LOGGERS_ORDER=DEBUGand restart the application.
Tip
Note that Spring normalizes the variable's suffix to lower case, for example, MY_LOGGERS_ORDER to my.loggers.order, which actually matches the package name. However, configuring a dedicated logger (such as my.loggers.order.Consolidation) can't work in general as class names are in camel case typically.
Tip
On SAP BTP, Cloud Foundry environment, you can add the environment variable with cf set-env <app name> LOGGING_LEVEL_MY_LOGGERS_ORDER DEBUG. Don't forget to restart the application with cf restart <app name> afterwards. The additional configuration endures an application restart but might be lost on redeployment.
At Runtime Without Restart
If configured, you can use Spring actuators to view and adjust logging configuration. Disregarding security aspects and provided that the loggers actuator is configured as HTTP endpoint on path /actuator/loggers, following example HTTP requests show how to accomplish this:
# retrieve state of all loggers:
curl https://<app-url>/actuator/loggers
# retrieve state of single logger:
curl https://<app-url>/actuator/loggers/my.loggers.oder.consolidation
#> {"configuredLevel":null,"effectiveLevel":"INFO"}
# Change logging level:
curl -X POST -H 'Content-Type: application/json' -d '{"configuredLevel": "DEBUG"}' \
https://<app-url>/actuator/loggers/my.loggers.oder.consolidationLearn more about Spring actuators and security aspects in the section Metrics.
Predefined Loggers
CAP Java SDK has useful built-in loggers that help to track runtime behavior:
| Logger | Use case |
|---|---|
com.sap.cds.security.authentication | Logs authentication and user information |
com.sap.cds.security.authorization | Logs authorization decisions |
com.sap.cds.odata.v2 | Logs OData V2 request handling in the adapter |
com.sap.cds.odata.v4 | Logs OData V4 request handling in the adapter |
com.sap.cds.handlers | Logs sequence of executed handlers as well as the lifecycle of RequestContexts and ChangeSetContexts |
com.sap.cds.persistence.sql | Logs executed queries such as CQN and SQL statements (w/o parameters) |
com.sap.cds.persistence.sql-tx | Logs transactions, ChangeSetContexts, and connection pool |
com.sap.cds.multitenancy | Logs tenant-related events and sidecar communication |
com.sap.cds.messaging | Logs messaging configuration and messaging events |
com.sap.cds.remote.odata | Logs request handling for remote OData calls |
com.sap.cds.remote.wire | Logs communication of remote OData calls |
com.sap.cds.auditlog | Logs audit log events |
com.sap.cds.outbox | Logs activity of the transactional outbox |
com.sap.cds.properties | Logs CDS properties with a non-default value on application startup |
Most of the loggers are used on DEBUG level by default as they produce quite some log output. It's convenient to control loggers on package level, for example, com.sap.cds.security covers all loggers that belong to this package (namely com.sap.cds.security.authentication and com.sap.cds.security.authorization).
Tip
Spring comes with its own standard logger groups. For instance, web is useful to track HTTP requests. However, HTTP access logs gathered by the Cloud Foundry platform router are also available in the application log.
Log CDS Configuration
Upon start-up, you can get an overview of the configured CDS properties. Use this feature to:
- list all accepted CDS properties and double-check the running configuration
- check for warnings of usage of deprecated properties
- check for warnings of usage of undocumented properties
Please note that secrets are masked.
Turn it on by setting the log level com.sap.cds.properties = DEBUG.
Sample output:
... DEBUG ... com.sap.cds.properties : 'cds.dataSource.autoConfig.enabled': 'false' (default: 'true')
... DEBUG ... com.sap.cds.properties : 'cds.dataSource.embedded': 'true' (default: 'false')
... WARN ... com.sap.cds.properties : 'cds.security.authorization.emptyAttributeValuesAreRestricted': 'false' (default: 'true', deprecated, not documented)
... DEBUG ... com.sap.cds.properties : 'cds.security.mock.users.admin.name': 'admin'
... DEBUG ... com.sap.cds.properties : 'cds.security.mock.users.admin.password': '***' (sensitive)
... DEBUG ... com.sap.cds.properties : 'cds.security.mock.users.admin.roles[0]': 'admin'
... DEBUG ... com.sap.cds.properties : 'cds.security.mock.users.admin.roles[1]': 'cds.Developer'
... DEBUG ... com.sap.cds.properties : 'cds.security.mock.users.admin.attributes.businessPartner[0]': '10401010'
... DEBUG ... com.sap.cds.properties : 'cds.odataV4.endpoint.path': '/api' (default: '/odata/v4')
... DEBUG ... com.sap.cds.properties : 'cds.errors.defaultTranslations.enabled': 'true' (default: 'false')Logging Service
The SAP BTP platform offers the SAP Application Logging service for SAP BTP and its recommended successor SAP Cloud Logging service to which bound Cloud Foundry applications can stream logs.
Establishing a connection is the same for both services: The application needs to be bound to the service. To match the log output format and structure expected by the logging service, it's recommended to use a prepared encoder from cf-java-logging-support that matches the configured logger framework. logback is used by default as outlined in Logging Frameworks:
<dependency>
<groupId>com.sap.hcp.cf.logging</groupId>
<artifactId>cf-java-logging-support-logback</artifactId>
<version>${logging.support.version}</version>
</dependency>By default, the library appends additional fields to the log output such as correlation id or Cloud Foundry space. To instrument incoming HTTP requests, a servlet filter needs to be created. See Instrumenting Servlets for more details.
During local development, you might want to stick to the (human-readable) standard log line format. This boils down to having different logger configurations for different Spring profiles. The following sample configuration outlines how you can achieve this. cf-java-logging-support is only active for profile cloud, since all other profiles are configured with the standard logback output format:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE xml>
<configuration debug="false" scan="false">
<springProfile name="cloud">
<!-- logback configuration of ConsoleAppender according
to cf-java-logging-support documentation -->
...
</springProfile>
<springProfile name="!cloud">
<include resource="org/springframework/boot/logging/logback/base.xml"/>
</springProfile>
</configuration>Tip
For an example of how to set up a multitenant aware CAP Java application with enabled logging service support, have a look at section Multitenancy > Adding Logging Service Support.
Correlation IDs
In general, a request can be handled by unrelated execution units such as internal threads or remote services. This fact makes it hard to correlate the emitted log lines of the different contributors in an aggregated view. The problem can be solved by enhancing the log lines with unique correlation IDs, which are assigned to the initial request and propagated throughout the call tree.
In case you've configured cf-java-logging-support as described in Logging Service before, correlation IDs are handled out of the box by the CAP Java SDK. In particular, this includes:
- Generation of IDs in non-HTTP contexts
- Thread propagation through Request Contexts
- Propagation to remote services when called via CloudSDK (for instance Remote Services or MTX sidecar)
By default, the ID is accepted and forwarded via HTTP header X-CorrelationID. If you want to accept X-Correlation-Id header in incoming requests alternatively, follow the instructions given in the guide Instrumenting Servlets.
JDBC Tracing in SAP Hana
To activate JDBC tracing in the SAP Hana JDBC driver, you have to use the driver Trace Options. You can activate it either by setting datasource properties in the application.yaml and restarting the application, or, while the application is running by using the command line.
Using datasource properties
In the application.yaml under cds.dataSource.<service-binding-name>: specify hikari.data-source-properties.traceFile and hikari.data-source-properties.traceOptions:
cds:
dataSource:
service-manager: # name of service binding
hikari:
data-source-properties:
traceFile: "/home/user/jdbctraces/trace_.log" # use a path that is write accessible
traceOptions: "CONNECTIONS,API,PACKET"Tip
Add an underscore at the end of the trace file's name. It helps redability by separating the string of numbers that the JDBC tracing process appends for the epoch timestamp.
~/jdbctraces/ $ ls
trace_10324282997834295561.log
trace_107295864860396783.log
trace_10832681394984179734.log
...Trace Options lists the available command line options. For the datasource property, you only need the option's name, such as CONNECTIONS, API, or PACKET. You can specify more than one option, separated by commas.
This method of activating JDBC tracing requires restarting the application. For cloud deployments on Cloud Foundry this typically means redeploying via MTA, on Kyma this means rebuilding the application, re-creating, and publishing the container image to the container image registry and redeploying the application via Helm.
Once the application.yaml of the deployed application contains both hikari.data-source-properties.traceFile and hikari.data-source-properties.traceOptions, their values can also be overwritten by setting the corresponding environment variables in the container.
For example, to overwrite the tracefile path for the application.yaml you have to set the environment variable such as this with SERVICE_MANAGER being the name of the service binding:
CDS_DATASOURCE_SERVICE_MANAGER_HIKARI_DATA_SOURCE_PROPERTIES_TRACEFILE: "/home/cnb/jdbctraces/sm/trace_.log"To overwrite the tracing options respectively:
CDS_DATASOURCE_SERVICE_MANAGER_HIKARI_DATA_SOURCE_PROPERTIES_TRACEOPTIONS: "DISTRIBUTIONS"Using the command line
Using the command line to activate JDBC tracing doesn't require an application restart.
However, when running in the cloud it depends on the buildpacks used for the CAP Java application where the exact location of the Hana JDBC driver and the java executable are. The following assumes the usage of the Cloud Native Buildpacks as recommended by the Unified Runtime.
On Kyma
Step-by-step description on how to access a bash session in the application's container to use trace options in the Hana JDBC driver:
Run bash in the pod that runs the CAP Java application:
First, identify the pod name:
shkubectl get podsin the right namespace run:
shkubectl exec -it pod/<POD_NAME> -- bashto acquire a bash session in the container.
Locate java executable and JDBC driver:
By default
JAVA_HOMEisn't set in the buildpack and contains minimal tooling, as it tries to minimize the container size. However, the default location of thejavaexecutable is/layers/paketo-buildpacks_sap-machine/jre/bin.For convenience, store the path into a variable, for example,
JAVA_HOME:shexport JAVA_HOME=/layers/paketo-buildpacks_sap-machine/jre/bin/The JDBC driver is usually located in
/workspace/BOOT-INF/lib. Store it into another variable, for example,JDBC_DRIVER_PATH:shexport JDBC_DRIVER_PATH=/workspace/BOOT-INF/libUse JDBC trace options in the driver, using the correct (versioned) name of the
ngdbc.jar:sh$JAVA_HOME/java -jar $JDBC_DRIVER_PATH/ngdbc-<VERSION>.jar <option>Trace Options lists the available options.
Before turning on tracing with
TRACE ON, it's recommended to setTRACE FILENAMEto a path that the current shell user has write access to, for example:sh$JAVA_HOME/java -jar $JDBC_DRIVER_PATH/ngdbc-<VERSION>.jar TRACE FILENAME ~/tmp/traces/jdbctraceRead the trace file while the pod is still running, or use
kubectl cpto copy the file to your local machine.
Monitoring
Connect your productive application to a monitoring tool to identify resource bottlenecks at an early stage and to take appropriate countermeasurements.
When connected to a monitoring tool, applications can report information about memory, CPU, and network usage, which forms the basis for resource consumption overview and reporting capabilities. In addition, call-graphs can be reconstructed and visualized that represent the flow of web requests within the components and services.
CAP Java integrates with the following monitoring tools:
Open Telemetry for reporting signals like distributed traces, logs, and metrics into Open Telemetry-compliant solutions. SAP Cloud Logging is supported with minimal configuration.
Dynatrace provides sophisticated features to monitor a solution on SAP BTP.
Spring Boot Actuators can help operators to quickly get an overview about the general status of the application on a technical level.
Availability checks are offered by SAP Cloud ALM for Operations.
Open Telemetry
Open Telemetry is an Open Source framework for observability in cloud applications. Applications can collect signals (distributed traces and metrics) and send them to observability front ends that offer a wide set of capabilities to analyze the current state or failures of an application. On SAP BTP, for example, the SAP Cloud Logging is offered as a front end for these purposes.
CAP Java applications can easily be configured to connect to SAP Cloud Logging or Dynatrace. In your CAP Java application, you configure one of these services inside the Open Telemetry configuration. Then the application automatically benefits from the following features:
- Out-of-the-box traces and metrics by auto-instrumented libraries and frameworks
- Additional traces for CAP-specific capabilities
- Automatic forwarding of telemetry signals (logs, traces, or metrics) to SAP BTP Cloud Logging or Dynatrace
- Full setup of Open Telemetry relevant configuration, including span hierarchy and Open Telemetry collectors
Spans and traces that are produced out of the box, include HTTP requests as well as CAP-specific execution of CQN statements or individual requests inside an OData $batch request. Metrics that are automatically provided, include standard JVM metrics like CPU and memory utilization.
In addition, it's possible to add manual instrumentations using the Open Telemetry Java API, for example, in a custom event handler.
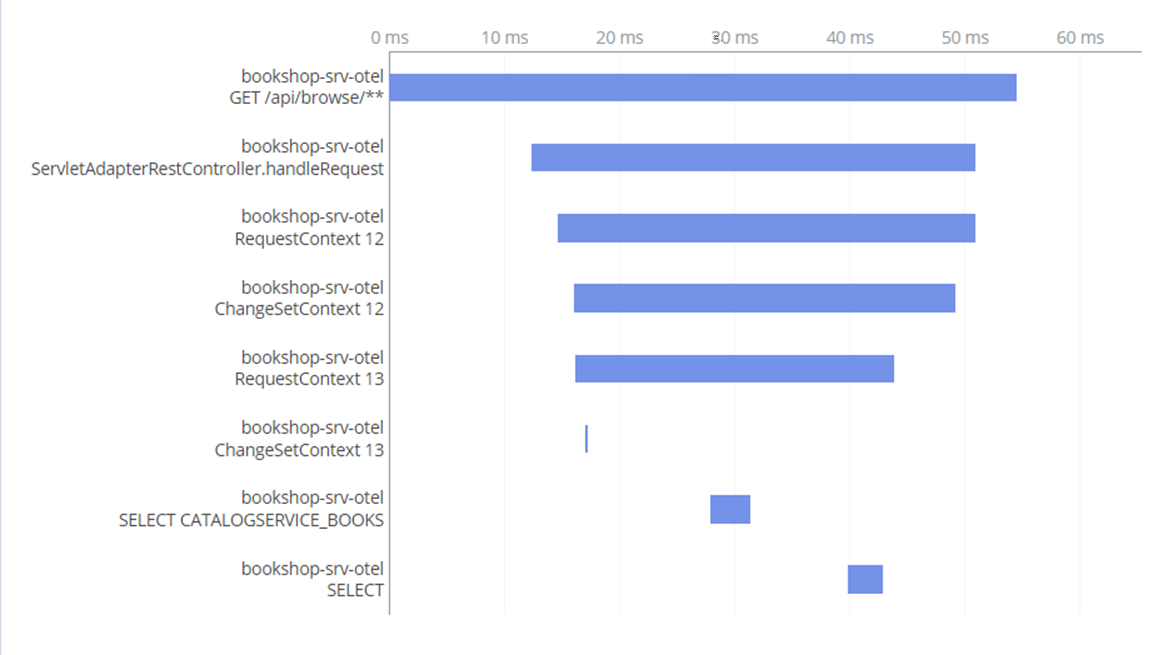
Configure Java Agent and Extension Library
Dependency
The configuration steps below assume that your application uses the SAP Java Buildpack.
Tip
You can conveniently enhance your application with Open Telemetry observability by running the command cds add cloud-logging --with-telemetry in your project directory.
Configure your application to enable the Open Telemetry Java Agent by adding or adapting the JBP_CONFIG_JAVA_OPTS parameter in your deployment descriptor:
- name: <srv-module>
# ...
properties:
# ...
JBP_CONFIG_JAVA_OPTS:
from_environment: false
java_opts: >
-javaagent:META-INF/.sap_java_buildpack/otel_agent/opentelemetry-javaagent.jar
-Dotel.javaagent.extensions=META-INF/.sap_java_buildpack/otel_agent_extension/otel-agent-ext-java.jarThe buildpack delivers the Open Telemetry Agent Extension library with the common configuration for Open Telemetry that applies to Cloud Logging Service and Dynatrace. This library provides out-of-the box configuration of the required credentials taken from the service bindings and more sophisticated configuration possibilities.
Learn more in the Open Telemetry Agent Extension library documentation
For troubleshooting purposes, you can increase the log level of the Open Telemetry Java Agent by adding the parameter -Dotel.javaagent.debug=true to the JBP_CONFIG_JAVA_OPTS argument.
Suppress auto-instrumentation for specific libraries
It's possible to suppress auto-instrumentation for specific libraries as described here. The corresponding -Dotel.instrumentation.[name].enabled=false parameter(s) can be added to the JBP_JAVA_OPTS argument.
Configuration of Cloud Logging Service
Open Telemetry support using SAP BTP Cloud Logging Service leverages the Open Telemetry Java Agent which needs to be attached to the CAP Java application. The following steps describe how this can be done:
Bind your CAP Java application to a service instance of
cloud-logging. It's important to enable the Open Telemetry capabilities by passingingest_otlpas additional configuration parameter. The following snippet shows an example how to add this to an mta.yaml descriptor:yamlmodules: - name: <srv-module> # ... requires: - name: cloud-logging-instance # ... resources: - name: cloud-logging-instance type: org.cloudfoundry.managed-service parameters: service: cloud-logging service-plan: standard config: ingest_otlp: enabled: true # ...Define additional environment variables to tell the agent extension to use Cloud Logging Service.
yaml- name: <srv-module> # ... properties: # ... OTEL_METRICS_EXPORTER: cloud-logging OTEL_TRACES_EXPORTER: cloud-logging OTEL_LOGS_EXPORTER: none
Configuration of Dynatrace
Open Telemetry support using Dynatrace leverages the Dynatrace OneAgent for distributed traces and Open Telemetry Java Agent for metrics. OpenTelemetry also can trace your application, but if you're using Dynatrace, it is better to leave the traces to the Dynatrace OneAgent to avoid trace duplication and inconsistencies in the trace data.
The following steps describe the required configuration:
- Follow the description to connect your CAP Java application to Dynatrace. Make sure that the service binding or user-provided service provides an API token for dynatrace with scope
metrics.ingest. The property name will be required in one of the following steps.
Open Telemetry support in OneAgent needs to be enabled once in your Dynatrace environment using the Dynatrace UI. Navigate to Settings > Preferences > OneAgent features and turn on the switch for OpenTelemetry (Java) as well as for OpenTelemetry Java Instrumentation agent support.
In addition, enable W3C Trace Context for proper context propagation between remote services. Navigate to Settings > Server-side service monitoring > Deep monitoring > Distributed tracing and turn on Send W3C Trace Context HTTP headers.
Define an additional environment variable to tell the agent extension to export metrics to Dynatrace via OpenTelemetry.
yaml- name: <srv-module> # ... properties: # ... OTEL_METRICS_EXPORTER: dynatrace OTEL_TRACES_EXPORTER: none OTEL_LOGS_EXPORTER: noneCheck your Dynatrace binding. You are looking for two tokens generated for you: the default one is called
apitokenand the second one should correspond to the token you have requested in yourmta.yamlor generated from Dynatrace instance manually.Add to the environment variable
JBP_CONFIG_JAVA_OPTSthe following option-Dotel.javaagent.extension.sap.cf.binding.dynatrace.metrics.token-name=<ingest_apitoken>. Replace the name<ingest_apitoken>with the name of the token you have found previously.Traces will be handled by the Dynatrace OneAgent and OpenTelemetry export for them is disabled to prevent the OpenTelemetry agent from interfering with that.
CAP Instrumentation
By default, instrumentation for CAP-specific components is disabled, so that no traces and spans are created even if the Open Telemetry Java Agent has been configured. It's possible to selectively activate specific spans by changing the log level for a component.
| Logger | Required Level | Description |
|---|---|---|
com.sap.cds.otel.span.ODataBatch | INFO | Spans for individual requests of a OData $batch request. |
com.sap.cds.otel.span.CQN | INFO | Spans for executed CQN statement. |
com.sap.cds.otel.span.OutboxCollector | INFO | Spans for execution of the transactional outbox collector. |
com.sap.cds.otel.span.DraftGarbageCollection | INFO | Spans for execution of the draft garbage collection. |
com.sap.cds.otel.span.RequestContext | DEBUG | Spans for each Request Context. |
com.sap.cds.otel.span.ChangeSetContext | DEBUG | Spans for each ChangeSet Context. |
com.sap.cds.otel.span.Emit | DEBUG | Spans for dispatching events in the CAP runtime. |
For specific steps to change the log level, please refer to the respective section for configuring logging.
Custom Instrumentation
Using the Open Telemetry Java API, it's possible to provide additional observability signals from within a CAP Java application. This can include additional spans as well as metrics.
You may use annotation-based instrumentation using the OpenTelemetry annotations for instrumenting your code or you can define your custom spans for places where you need a lot of context or require the advanced features of the OpenTelemetry API.
To enable annotation-based tracing, include the following dependency in your pom.xml:
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-instrumentation-annotations</artifactId>
<version>2.3.0</version>
</dependency>Then, you can create additional spans around your event handlers just by annotating their methods with the annotation @WithSpan. Such spans will react on exceptions and by default they will have class and method name as the description.
@Component
@ServiceName(CatalogService_.CDS_NAME)
class CatalogServiceHandler implements EventHandler {
@Before(entity = Books_.CDS_NAME)
@WithSpan
public void beforeAddReview(AddReviewContext context) {
// ...
}
}Learn more about the features of annotation-based spans.
To use OpenTelemetry API for more complex spans, add a dependency to the Open Telemetry Java API in the pom.xml of the CAP Java application:
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-api</artifactId>
</dependency>The instance of OpenTelemetry API is preconfigured for you by the agent that was injected in your application. You don't need to configure it again.
The following example produces an additional span when the @After handler is executed. The Open Telemetry API automatically ensures that the span is correctly added to the current span hierarchy. Span attributes allow an application to associate additional data to the span, which helps to identify and to analyze the span. Exceptions that were thrown within the span should be associated with the span using the recordException method. This marks the span as erroneous and helps to analyze failures. It's important to close the span in any case. Otherwise, the span isn't recorded and is lost.
@Component
@ServiceName(CatalogService_.CDS_NAME)
class CatalogServiceHandler implements EventHandler {
Tracer tracer = GlobalOpenTelemetry.getTracerProvider()
.tracerBuilder("RatingCalculator").build();
@After(entity = Books_.CDS_NAME)
public void afterAddReview(AddReviewContext context) {
Span childSpan = tracer.spanBuilder("setBookRating").startSpan();
childSpan.setAttribute("book.title", context.getResult().getTitle());
childSpan.setAttribute("book.id", context.getResult().getBookId());
childSpan.setAttribute("book.rating", context.getResult().getRating());
try(Scope scope = childSpan.makeCurrent()) {
ratingCalculator.setBookRating(context.getResult().getBookId());
} catch (Throwable t) {
childSpan.recordException(t);
throw t;
} finally {
childSpan.end();
}
}
}Learn more about the features of the instrumentation API
You can record metrics during execution of, for example, a custom event handler. The following example manages a metric reviewCounter, which counts the number of book reviews posted by users. Adding the bookId as additional attribute improves the value of the data as this can be handled by the Open Telemetry front end as dimension for aggregating values of this metric.
@Component
@ServiceName(CatalogService_.CDS_NAME)
class CatalogServiceHandler implements EventHandler {
Meter meter = GlobalOpenTelemetry.getMeterProvider().meterBuilder("RatingCalculator").build();
@After(entity = Books_.CDS_NAME)
public void afterAddReview(AddReviewContext context) {
ratingCalculator.setBookRating(context.getResult().getBookId());
LongCounter counter = meter.counterBuilder("reviewCounter")
.setDescription("Counts the number of reviews created per book")
.build();
counter.add(1, Attributes.of(AttributeKey.stringKey("bookId"),
context.getResult().getBookId()));
}
}Dynatrace
Dynatrace is a comprehensive platform that delivers analytics and automation based on monitoring events sent by the backend services. It requires OneAgent that runs in the backend capturing monitoring data and sending to the Dynatrace service.
How to configure a Dynatrace connection to your CAP Java application is described in Dynatrace Integration.
Spring Boot Actuators
Metrics are mainly referring to operational information about various resources of the running application, such as HTTP sessions and worker threads, JDBC connections, JVM memory including garbage collector statistics and so on. Similar to health checks, Spring Boot comes with a bunch of built-in metrics based on the Spring Actuator framework. Actuators form an open framework, which can be enhanced by libraries (see CDS Actuator) as well as the application (see Custom Actuators) with additional information.
Spring Boot Actuators are designed to provide a set of out-of-the-box supportability features, that help to make your application observable in production.
To add actuator support in your application, add the following dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>The following table lists some of the available actuators that might be helpful to understand the internal status of the application:
| Actuator | Description |
|---|---|
metrics | Thread pools, connection pools, CPU, and memory usage of JVM and HTTP web server |
beans | Information about Spring beans created in the application |
env | Exposes the full Spring environment including application configuration |
loggers | List and modify application loggers |
By default, nearly all actuators are active. You can switch off actuators individually in the configuration. The following configuration turns off flyway actuator:
management.endpoint.flyway.enabled: falseDepending on the configuration, exposed actuators can have HTTP or JMX endpoints. For security reasons, it's recommended to expose only the health actuator as web endpoint as described in Health Indicators. All other actuators are recommended for local JMX-based access as described in JMX-based Tools.
CDS Actuator
CAP Java SDK plugs a CDS-specific actuator cds. This actuator provides information about:
- The version and commit ID of the currently used
cds-serviceslibrary - All services registered in the service catalog
- Security configuration (authentication type and so on)
- Loaded features such as
cds-feature-identity - Database pool statistics (requires
registerMbeans: truein Hikari pool configuration)
Custom Actuators
Similar to Custom Health Indicators, you can add application-specific actuators as done in the following example:
@Component
@ConditionalOnClass(Endpoint.class)
@Endpoint(id = "app", enableByDefault = true)
public class AppActuator {
@ReadOperation
public Map<String, Object> info() {
Map<String, Object> info = new LinkedHashMap<>();
info.put("Version", "1.0.0");
return info;
}
}The AppActuator bean registers an actuator with name app that exposes a simple version string.
Availability
This section describes how to set up an endpoint for availability or health check. At a first glance, providing such a health check endpoint sounds like a simple task. But some aspects need to be considered:
- Authentication (for example, Basic or OAuth2) increases security but introduces higher configuration and maintenance effort.
- Only low resource consumption can be introduced. If you provide a public endpoint, only low overhead is accepted to avoid denial-of-service attacks.
- Ideally, the health check response shows not only the aggregate status, but also the status of crucial services the application depends on such as the underlying persistence.
Spring Boot Health Checks
Conveniently, Spring Boot offers out-of-the-box capabilities to report the health of the running application and its components. Spring provides a bunch of health indicators, especially PingHealthIndicator (/ping) and DataSourceHealthIndicator (/db). This set can be extended by custom health indicators if necessary, but most probably, setting up an appropriate health check for your application is just a matter of configuration.
To do so, first add a dependency to Spring Actuators, which forms the basis for health indicators:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>By default, Spring exposes the aggregated health status on web endpoint /actuator/health, including the result of all registered health indicators. But also the info actuator is exposed automatically, which might be not desired for security reasons. It's recommended to explicitly control web exposition of actuator components in the application configuration. The following configuration snippet is an example suitable for public visible health check information:
management:
endpoint:
health:
show-components: always # shows individual indicators
endpoints:
web:
exposure:
include: health # only expose /health as web endpoint
health:
defaults.enabled: false # turn off all indicators by default
ping.enabled: true
db.enabled: trueThe example configuration makes Spring exposing only the health endpoint with health indicators db and ping. Other indicators ready for auto-configuration such as diskSpace are omitted. All components contributing to the aggregated status are shown individually, which helps to understand the reason for overall status DOWN.
Tip
For multitenancy scenarios, CAP Java replaces the default db indicator with an implementation that includes the status of all tenant databases.
In addition CAP Java offers a health indicator modelProvider. This health indicator allows to include the status of the MTX sidecar serving the Model Provider Service.
management:
health:
modelProvider.enabled: trueWarning
The modelProvider health indicator requires @sap/cds version 7.8.0 or higher in MTX sidecar.
Endpoint /actuator/health delivers a response (HTTP response code 200 for up, 503 for down) in JSON format with the overall status property (for example, UP or DOWN) and the contributing components:
{
"status": "UP",
"components": {
"db": {
"status": "UP"
},
"ping": {
"status": "UP"
}
}
}It might be advantageous to expose information on a detailed level. This configuration is only an option for a protected health endpoint:
management.endpoint.health.show-details: alwaysBe mindful about data exposure and resource consumption
A public health check endpoint may neither disclose system internal data (for example, health indicator details) nor introduce significant resource consumption (for example, doing synchronous database request).
Find all details about configuration opportunities in Spring Boot Actuator documentation.
Custom Health Indicators
In case your application relies on additional, mandatory services not covered by default health indicators, you can add a custom health indicator as sketched in this example:
@Component("crypto")
@ConditionalOnEnabledHealthIndicator("crypto")
public class CryptoHealthIndicator implements HealthIndicator {
@Autowired
CryptoService cryptoService;
@Override
public Health health() {
Health.Builder status = cryptoService.isAvailalbe() ?
Health.up() : Health.down();
return status.build();
}
}The custom HealthIndicator for the mandatory CryptoService is registered by Spring automatically and can be controlled with property management.health.crypto.enabled: true.
Protected Health Checks
Optionally, you can configure a protected health check endpoint. On the one hand this gives you higher flexibility with regards to the detail level of the response but on the other hand introduces additional configuration and management efforts (for instance key management). As this highly depends on the configuration capabilities of the client services, CAP doesn't come with an auto-configuration. Instead, the application has to provide an explicit security configuration on top as outlined with ActuatorSecurityConfig in Customizing Spring Boot Security Configuration.